【编译】Pathways 语言模型 (PaLM):扩展到 5400 亿个参数以获得突破性性能
本文目录
- 原文标题:Pathways Language Model (PaLM): Scaling to 540 Billion Parameters for Breakthrough Performance
- 原文链接:https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html
- 原文作者:Google Search 软件工程师 Sharan Narang 和 Aakanksha Chowdhery
- 原文日期:2022 年 4 月 4 日
近年来,为语言理解和生成而训练的大型神经网络在广泛的任务中取得了令人瞩目的成果。 GPT-3 首先展示了大型语言模型 (LLM) 可用于少样本学习,无需大规模任务特定数据收集或模型参数更新即可取得令人印象深刻的结果。 最近的 LLM,例如 GLaM、LaMDA、Gopher 和 Megatron-Turing NLG,通过缩放模型大小、使用稀疏激活模块以及在来自更多数据集的更大数据集上进行训练,在许多任务上取得了最先进的小样本结果。 来源多样。 然而,在我们推动模型规模的极限时,要理解小样本学习所出现的能力,还有很多工作要做。
去年,Google Research 宣布了我们对 Pathways 的愿景,这是一种单一模型,可以在高效的同时跨领域和任务进行泛化。 实现这一愿景的一个重要里程碑是开发新的 Pathways 系统来为加速器编排分布式计算。 在“PaLM: Scaling Language Modeling with Pathways”中,我们介绍了 Pathways Language Model (PaLM),这是一个 5400 亿参数、密集解码器的 Transformer 模型,使用 Pathways 系统训练,使我们能够有效地跨多个模型训练单个模型 TPU v4 Pod。 我们在数百个语言理解和生成任务上评估了 PaLM,发现它在大多数任务中都实现了最先进的小样本性能,在许多情况下都有很大的优势。
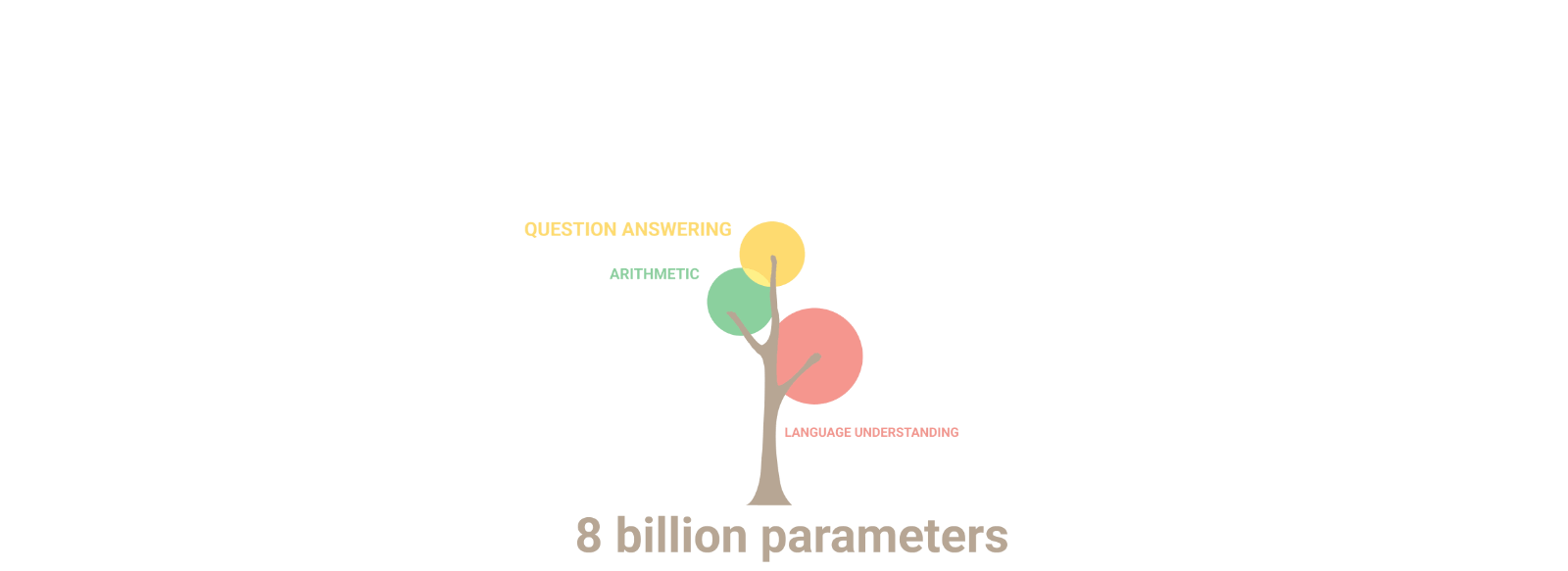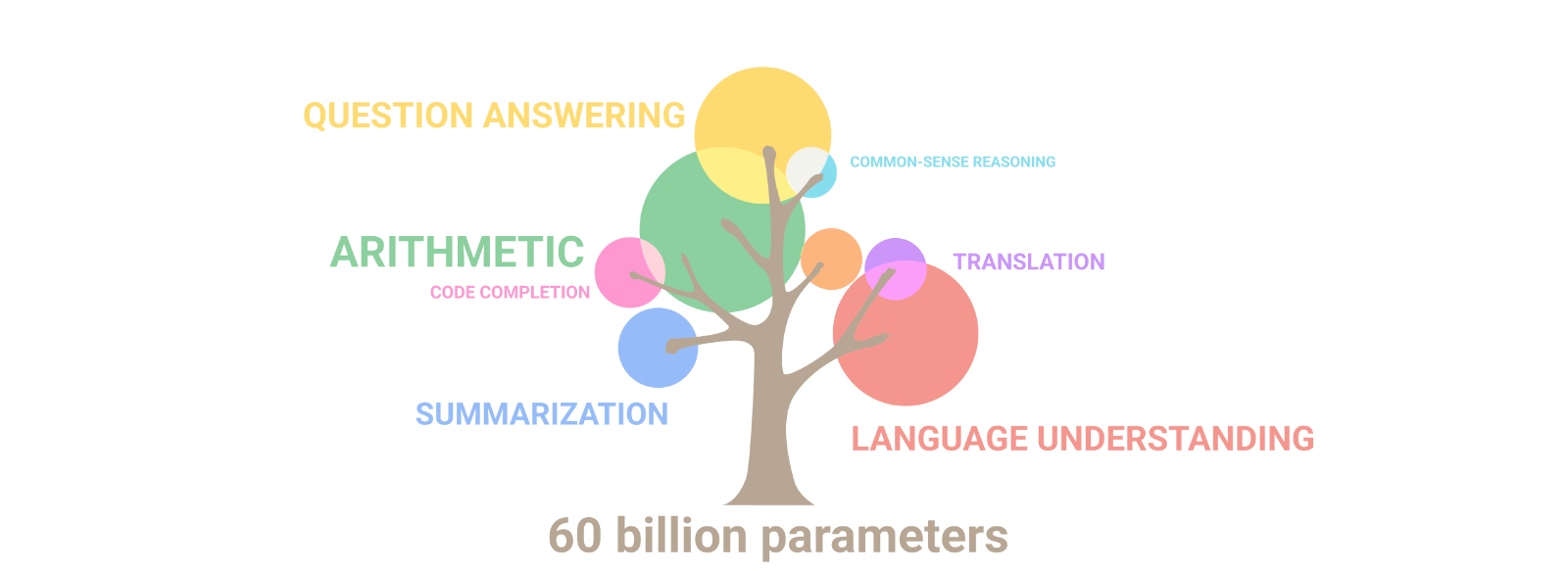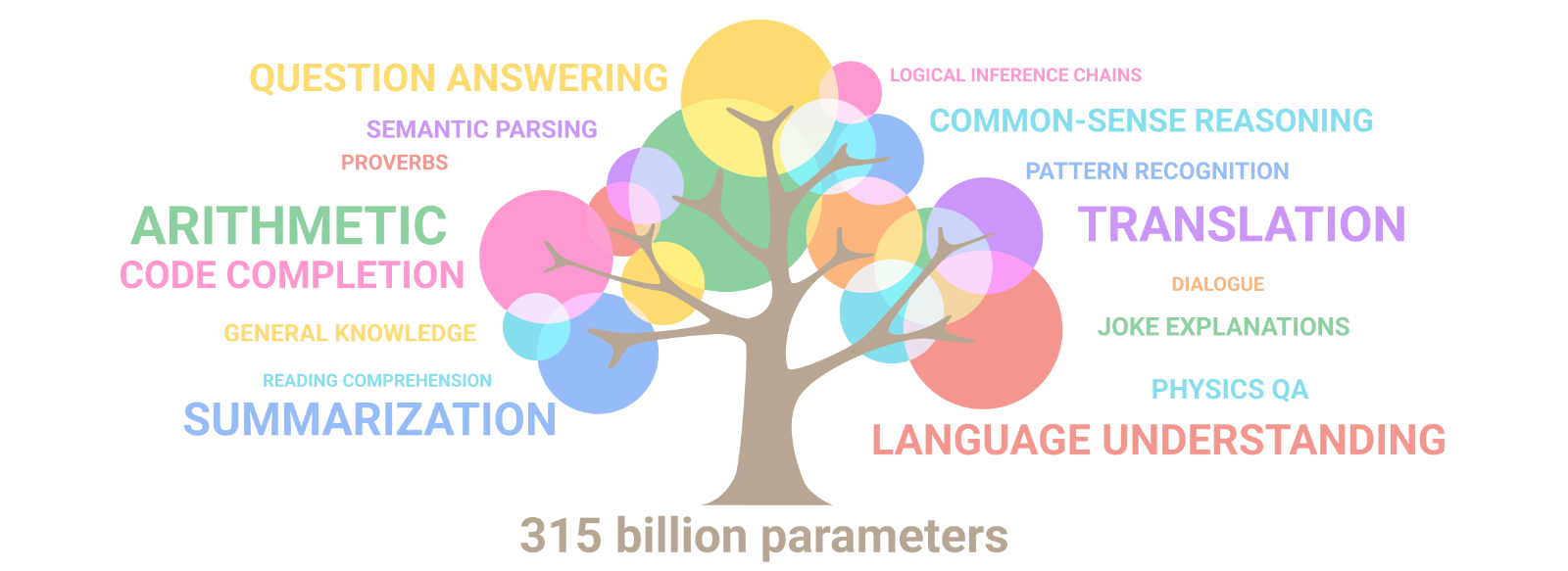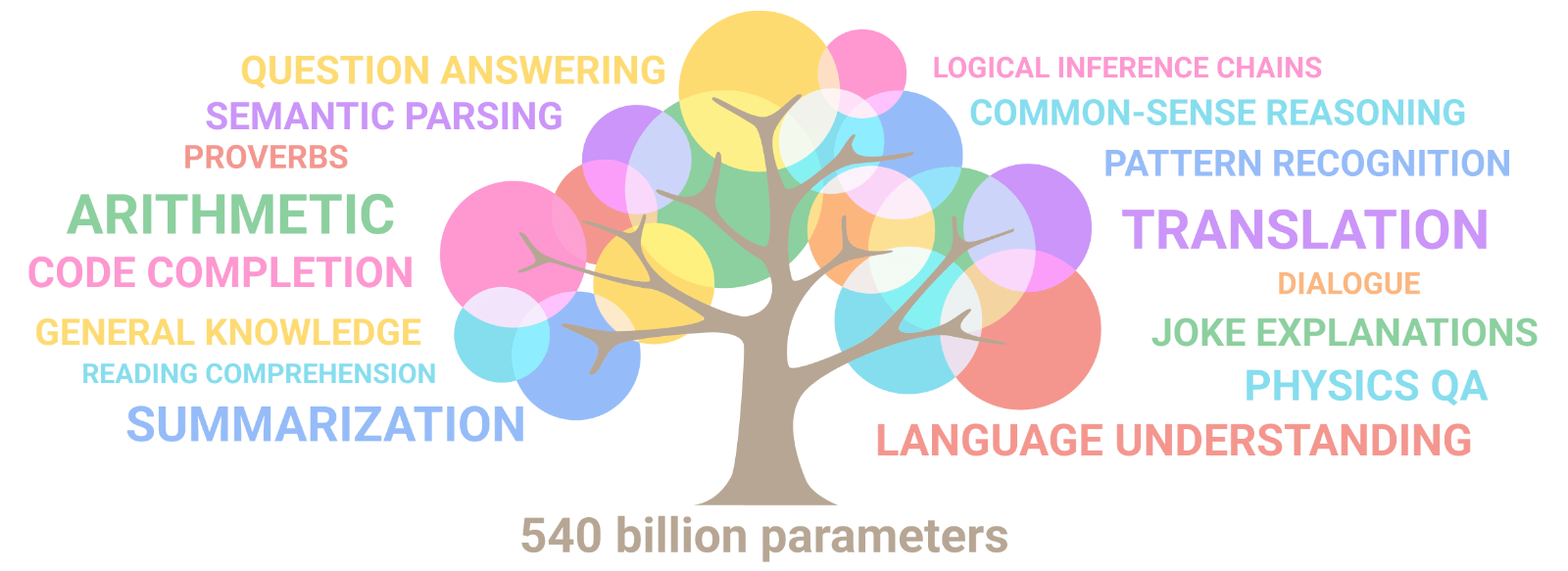
随着模型规模的增加,跨任务的性能会提高,同时还会解锁新功能。
使用 Pathways 训练一个 5400 亿参数的语言模型
PaLM 首次大规模使用 Pathways 系统将训练扩展到 6144 个芯片,这是迄今为止用于训练的最大的基于 TPU 的系统配置。 训练在两个 Cloud TPU v4 Pod 之间使用 Pod 级别的数据并行性进行扩展,同时在每个 Pod 内使用标准数据和模型并行性。 与大多数以前的 LLM 相比,这是规模的显着增加,这些 LLM 在单个 TPU v3 Pod(例如 GLaM、LaMDA)上进行训练,使用流水线并行性跨 GPU 集群(Megatron-Turing NLG)扩展到 2240 个 A100 GPU,或者 使用了多个 TPU v3 Pod(Gopher),最大规模为 4096 个 TPU v3 芯片。
PaLM 实现了 57.8% 的硬件 FLOPs 利用率的训练效率,这是 LLM 在此规模上达到的最高水平。 这是由于结合了并行策略和 Transformer 块的重新制定,允许并行计算注意力和前馈层,从而实现 TPU 编译器优化的加速。
PaLM 使用英语和多语言数据集的组合进行训练,这些数据集包括高质量的网络文档、书籍、维基百科、对话和 GitHub 代码。 我们还创建了一个“无损”词汇表,保留所有空格(对代码尤其重要),将词汇外的 Unicode 字符拆分为字节,并将数字拆分为单独的标记,每个标记一个。
语言、推理和代码任务的突破性能力
PaLM 在许多非常困难的任务上显示出突破性的能力。 我们在下面重点介绍了语言理解和生成、推理以及与代码相关的任务的几个示例。
语言理解与生成
我们在 29 个广泛使用的英语自然语言处理 (NLP) 任务上评估了 PaLM。 PaLM 540B 在 29 个跨越问答任务(开放域封闭- book variant)、完形填空和句子完成任务、Winograd 风格任务、上下文阅读理解任务、常识推理任务、SuperGLUE 任务和自然语言推理任务。
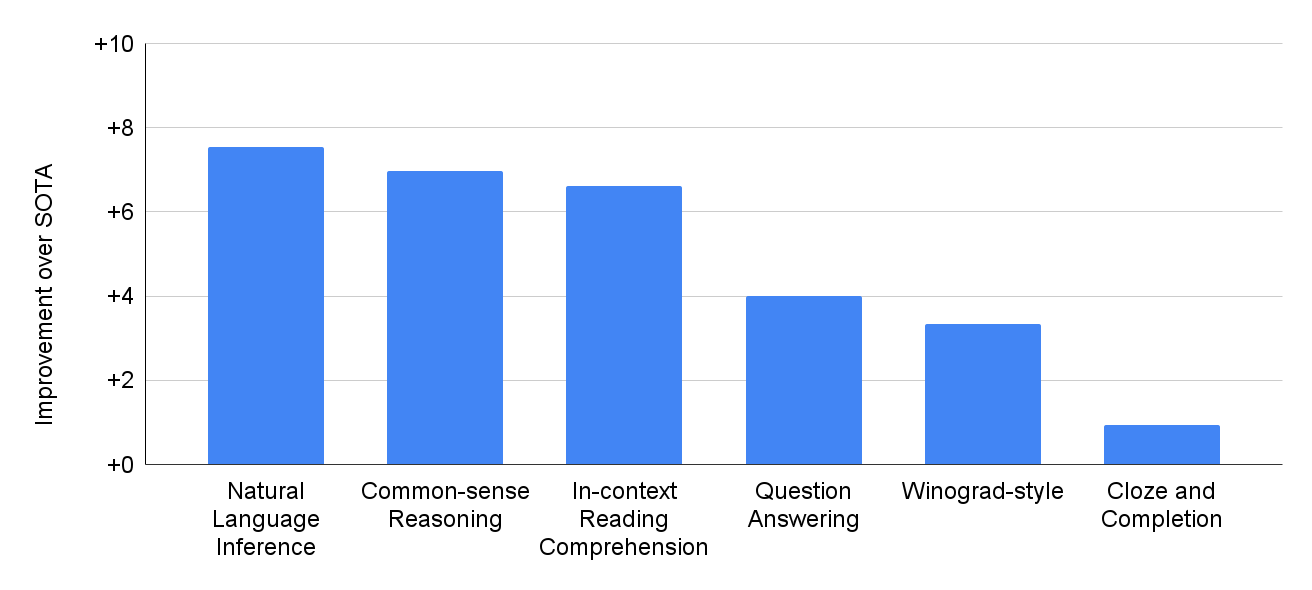
↑ 在 29 个基于英语的 NLP 任务上,PaLM 540B 的性能比之前最先进 (SOTA) 的结果有所提高。
除了英语 NLP 任务外,PaLM 在多语言 NLP 基准测试中也表现出色,包括翻译,尽管只有 22% 的训练语料库是非英语的。
我们还在 Beyond the Imitation Game Benchmark (BIG-bench) 上探索了 PaLM 的新兴和未来功能,这是最近发布的包含 150 多个新语言建模任务的套件,并发现 PaLM 实现了突破性的性能。 我们比较了 PaLM 与 Gopher 和 Chinchilla 的性能,在这些任务的 58 个公共子集中取平均值。 有趣的是,我们注意到 PaLM 作为规模函数的性能遵循与先前模型相似的对数线性行为,这表明规模带来的性能改进尚未达到稳定水平。 PaLM 540B 5-shot 的表现也优于人们要求解决相同任务的平均表现。
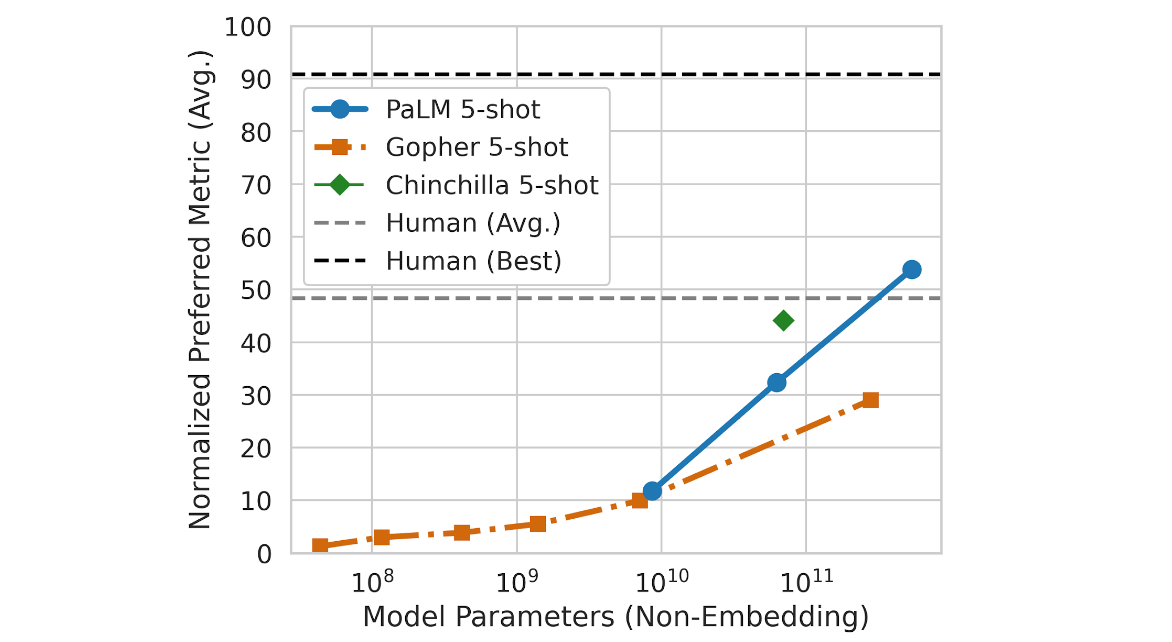
↑ PaLM 在 58 个 BIG-bench 任务的子集上的缩放行为。
PaLM 在几个 BIG-bench 任务上展示了令人印象深刻的自然语言理解和生成能力。 为了考试例如,该模型可以区分因果关系,理解适当上下文中的概念组合,甚至可以根据表情符号猜测电影。

↑ 展示 PaLM 540B 在 BIG-bench 任务上的 1-shot 性能的示例:标记因果关系、概念理解、根据表情符号猜测电影,以及寻找同义词和反事实。
推理
通过将模型规模与思维链提示相结合,PaLM 在需要多步算术或常识推理的推理任务上显示出突破性的能力。 之前的 LLM,如 Gopher,认为模型规模在提高性能方面的好处较少。

↑ 标准提示与思维链提示的示例小学数学问题。 思维链提示将多步推理问题的提示分解为中间步骤(以黄色突出显示),类似于人处理它的方式。
我们在三个算术数据集和两个常识推理数据集上观察到 PaLM 540B 结合思维链提示的强大性能。 例如,通过 8 次提示,PaLM 解决了 GSM8K 中 58% 的问题,GSM8K 是数千个具有挑战性的小学水平数学问题的基准,优于之前通过微调 GPT-3 175B 模型获得的 55% 的最高分 具有 7500 个问题的训练集,并将其与外部计算器和验证器相结合。
这个新分数特别有趣,因为它接近 9-12 岁儿童解决问题的平均 60%,他们是问题集的目标受众。 我们怀疑 PaLM 词汇表中的数字单独编码有助于实现这些性能改进。
值得注意的是,PaLM 甚至可以为需要多步逻辑推理、世界知识和深度语言理解的复杂组合的场景生成明确的解释。 例如,它可以为网络上找不到的小说笑话提供高质量的解释。
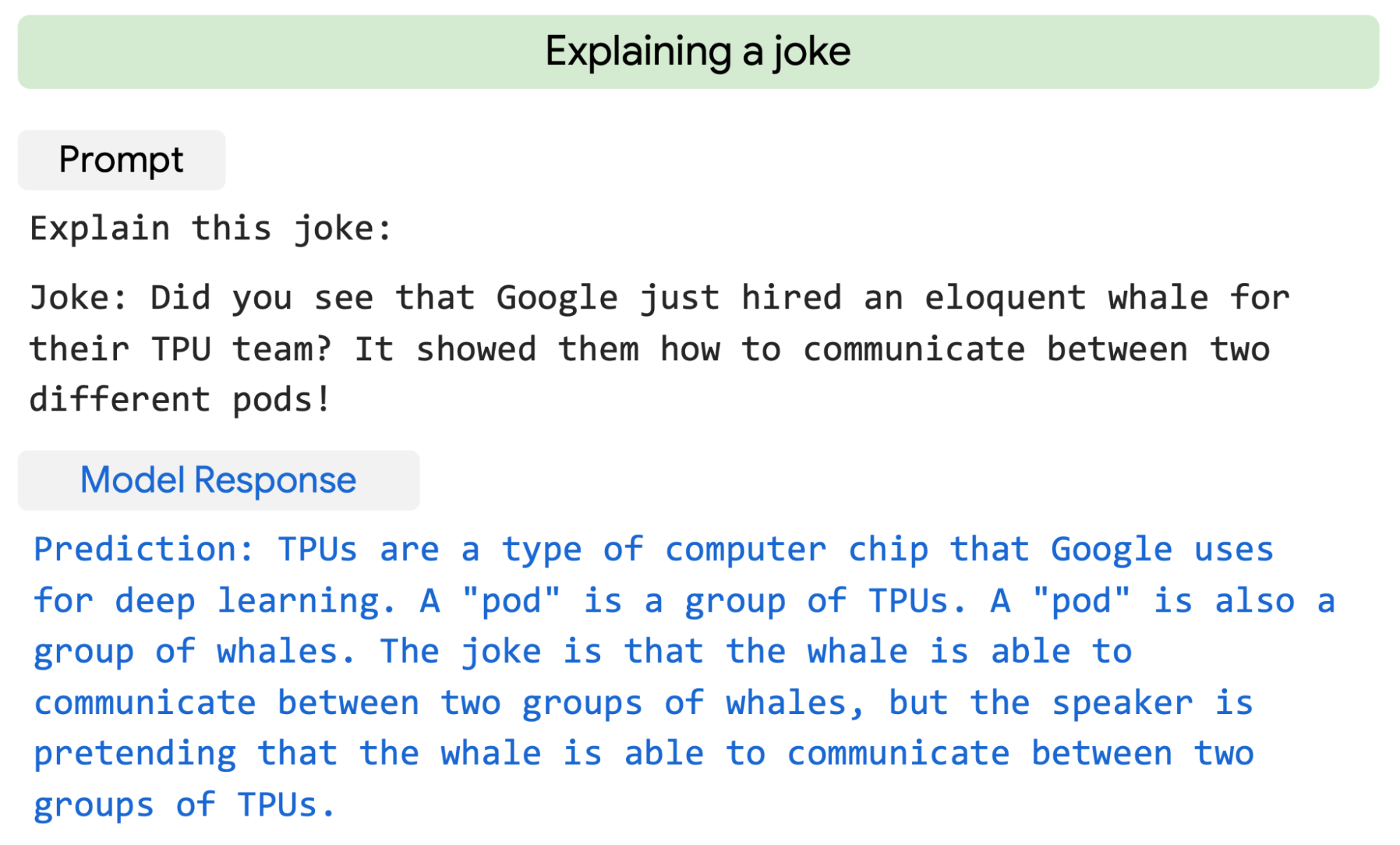
↑ PaLM 用两次提示解释了一个原创笑话。
代码生成
LLM 也被证明 [1, 2, 3, 4] 可以很好地泛化到编码任务,例如编写给定自然语言描述的代码(文本到代码),将代码从一种语言翻译成另一种语言,以及修复编译错误 (代码到代码)。
PaLM 540B 在单个模型中跨编码任务和自然语言任务显示出强大的性能,即使它在预训练数据集中只有 5% 的代码。 它的 few-shot 性能尤其出色,因为它与经过微调的 Codex 12B 相当,同时使用的 Python 代码少了 50 倍进行训练。 这一结果强化了之前的发现,即较大的模型可以比较小的模型更有效地采样,因为它们更有效地从其他编程语言和自然语言数据中迁移学习。

↑ 在文本到代码任务(例如 GSM8K-Python 和 HumanEval)和代码到代码任务(例如 Transcoder)上经过微调的 PaLM 540B 模型示例。
通过在纯 Python 代码数据集上微调 PaLM,我们还看到了性能的进一步提高,我们称之为 PaLM-Coder。 对于名为 DeepFix 的示例代码修复任务,其目标是修改最初损坏的 C 程序,直到它们成功编译,PaLM-Coder 540B 展示了令人印象深刻的性能,实现了 82.1% 的编译率,优于之前的 71.7% 的现有技术水平 . 这为修复软件开发过程中出现的更复杂的错误提供了机会。
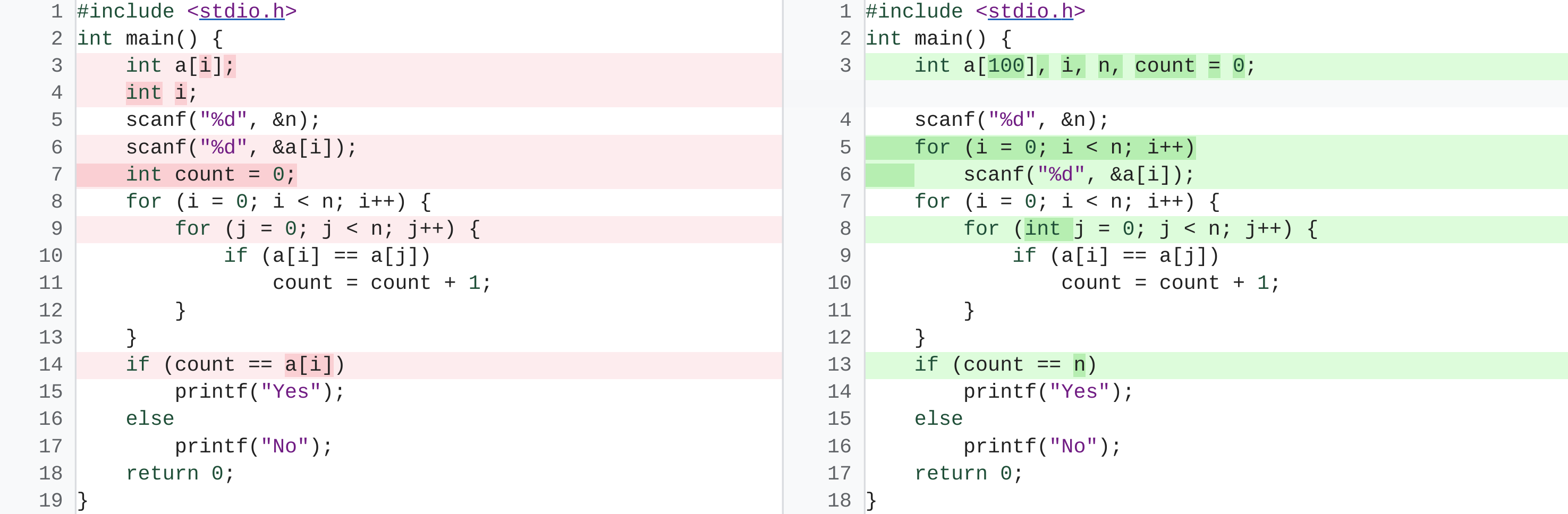
来自 DeepFix 代码修复任务的示例。 经过微调的 PaLM-Coder 540B 将编译错误(左,红色)修复为可编译的代码版本(右)。
道德考量
最近的研究强调了与接受网络文本培训的法学硕士相关的各种潜在风险。
通过模型卡和数据表等透明工件分析和记录此类潜在的不良风险至关重要,其中还包括有关预期用途和测试的信息。 为此,我们的论文提供了数据表、模型卡和 Responsible AI 基准测试结果,并报告了对数据集和模型输出的偏差和风险的全面分析。 虽然分析有助于概述模型的一些潜在风险,但针对特定领域和任务的分析对于真正校准、情境化和减轻可能的危害至关重要。 进一步了解这些模型的风险和好处是正在进行的研究的主题,同时开发可扩展的解决方案可以防止恶意使用语言模型。
结论和未来的工作
PaLM 展示了 Pathways 系统在两个 TPU v4 Pod 上扩展到数千个加速器芯片的扩展能力,方法是使用经过充分研究、完善的密集解码器 Transformer 模型有效地训练一个 5400 亿个参数模型。 突破模型规模的极限,使 PaLM 在各种自然语言处理、推理和代码任务中实现突破性的小样本性能。
PaLM 通过以下方式为功能更强大的模型铺平了道路将扩展能力与新颖的架构选择和培训方案相结合,使我们更接近 Pathways 的愿景:
“使单个 AI 系统能够概括数千或数百万个任务,理解不同类型的数据,并以惊人的效率完成这些任务。”
致谢
PaLM 是 Google Research 和整个 Alphabet 的许多团队共同努力的结果。 我们要感谢整个 PaLM 团队的贡献:Jacob Devlin、Maarten Bosma、Gaurav Mishra、Adam Roberts、Paul Barham、Hyung Won Chung、Charles Sutton、Sebastian Gehrmann、Parker Schuh、Kensen Shi、Sasha Tsvyashchenko、Joshua Maynez , Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya , Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick、Andrew Dai、Thanumalayan Sankaranarayana Pillai、Marie Pellat、Aitor Lewkowycz、Erica Moreira、Rewon Child、Oleksandr Polozov、Katherine Lee、Zongwei Zhou、Xuezhi Wang、Brennan Saeta、Mark Diaz、Orhan Firat、Michele Catasta 和 Jason Wei。 PaLM 建立在谷歌许多团队的工作之上,我们特别要感谢 T5X 团队、Pathways 基础设施团队、JAX 团队、Flaxformer 团队、XLA 团队、Plaque 团队、Borg 团队,以及 数据中心网络基础架构团队。 我们要感谢这篇博文的共同作者 Alexander Spiridonov 和 Maysam Moussalem,以及 Josh Newlan 和 Tom Small 在这篇博文中提供的图像和动画。 最后,我们要感谢我们的项目顾问:Noah Fiedel、Slav Petrov、Jeff Dean、Douglas Eck 和 Kathy Meier-Hellstern。