开源 LLM 革命之 1:Meta 推出开源 LLaMA,用 1/10 参数规模打败 GPT-3,群"模"乱舞的 2023 拉开序幕

北京时间 2023 年 2 月 25 日 Meta AI 在其官网公开发布了 LLaMA(Large Language Model Meta AI)大型语言模型,包括 70 亿、130 亿、330 亿、650 亿 4 种参数规模,旨在推动 LLM 领域的小型化、平民化研究。有趣的是,LLaMA 是羊驼的意思。
Guillaume Lample 在其 Twitter 上声称:LLaMA 130 亿参数版本的表现,在大多数测试上优于 OPT 和 GPT-3 1750 亿参数版,650 亿的版本表现基本可以比肩 Chinchilla 700 亿参数、PaLM 5400 亿参数这些大模型。
LLaMA 是由 Meta AI 的 FAIR 团队研发的,在 2022 年 12 月到 2023 年 2 月期间进行的训练,目前 GitHub 上放出的是这个模型的 V1 版(Version 1)。与 GPT 系列类似,LLaMA 也是一个建立在 Transformer 基础架构上的自回归语言模型(Autoregression Language Model),关于 Transformer 基础架构不了解的朋友可以阅读这篇文章《人工智能 LLM 革命前夜:一文读懂横扫自然语言处理的 Transformer 模型》。
- 源码:https://github.com/facebookresearch/llama
- 论文:https://research.facebook.com/file/1574548786327032/LLaMA–Open-and-Efficient-Foundation-Language-Models.pdf Meta AI 同时在其官方发布了论文《LLaMA: Open and Efficient Foundation Language Models》

下面我们根据目前 LLaMA 公开的信息,第一时间快速浏览一些关键信息。
1、模型参数及基本原理
像其他大型语言模型一样,LLaMA 也是通过将一系列单词作为输入,并预测下一个单词以递归生成文本。为了训练你们的模型,你们选择了使用最广泛的20种语言的文本,重点关注拉丁字母和西里尔字母的语言。
模型架构上,也是基于 Transformer,但是做了几个显著的改进:
- 从 GPT-3 得到启发的 Pre-normalization:为了增强训练的稳定性,将只在输出层的 normalization 改成了 Transformer 里面每一层的输入都进行 normalize,具体用的是 Zhang and Sennrich (2019) 提到的 RMSNorm[1]。
- 从 PaLM 得到启发的 SwiGLU 激活函数:用 Shazeer(2020) 提到的 SwiGLU 激活函数[2]替换了大家熟悉的 ReLU 激活函数。
- 从 GPTNeo 得到启发的 RoPE:在 Transformer 位置编码部分,没有用绝对位置编码(Absoute Positional Embeddings),而是用的 Su et al.(2021) [3] 提到的 RoPE(Rotary Positional Embeddings)。
Meta AI 公布了其各尺寸 LLaMA 模型的超参数:
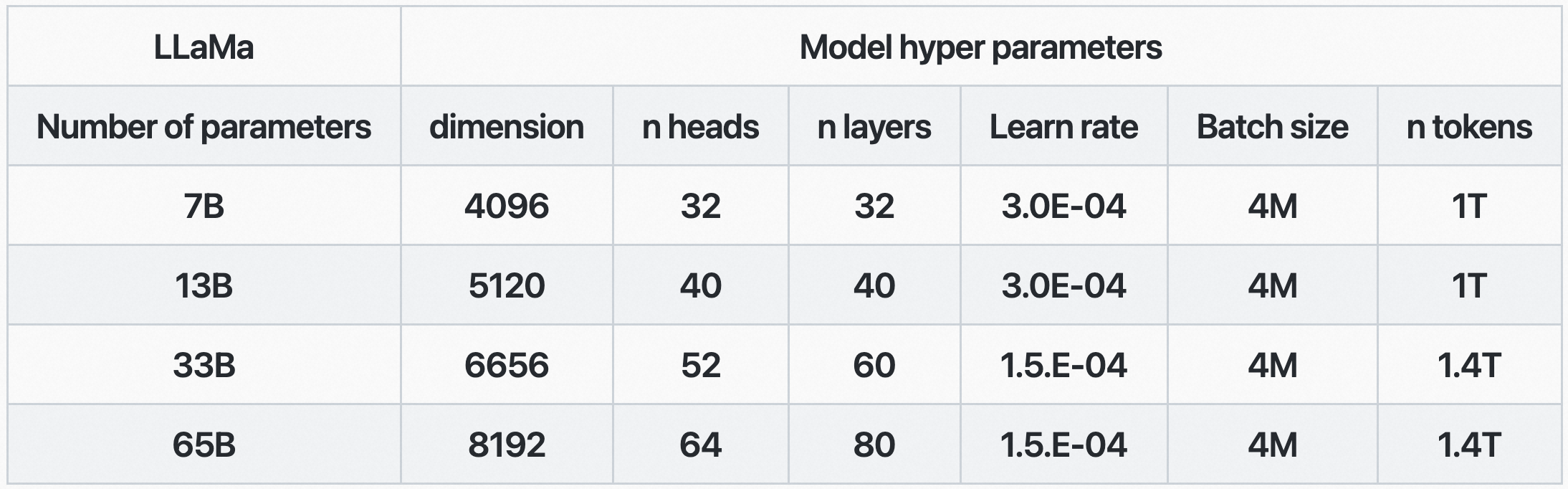
与 GPT-3 模型对比可以看出,LLaMA 的四个版本中:
- LLaMA-7B 对应的是 GPT-3 6.7B 版本,都是 32 层、32 个多头注意力、4096 宽度,LR 3.0E-4 要高于 GPT 的 1.2E-4,batch 4M 更大
- LLaMA-13B 对应的是 GPT-3 13B 版本,都是 40 层、40 个多头注意力,模型宽度 5120、5140 差不多,LR 3.0E-4 也高于 GPT 的 1.0E-4,batch 4M 更大
- LLaMA-33B、LLaMA-65B 与 GPT-3 就没有对应了,都是仅次于 GPT-3 最大的 175B 版本。Meta AI 也是为了证明,更小的模型也能达到甚至超越 GPT-3 暴力大模型,这也是推动模型小型化的一个动力。
2、数据
LLaMA 的训练数据
LLaMA 用到了如下这些训练数据集,并给出了相应的占比:
- CCNet:67%
- C4:15%,NLP 领域的人也基本知道了,全称是 Colossal Common Crawl Corpus,最早大家了解到它基本是通过 Google T5 模型的那篇论文《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》。作为对比,GPT-3 中的 60% 数据来自 Common Crawl,不过 GPT-3 对其 Common Crawl 的数据以及此前 OpenAI 在 GPT-2 用的 WebText 作为训练数据参照对 Common Crawl 数据进行了正类、负类的分类清理,不过还不是 C4。
- GitHub:4.5%,开源代码仓库平台,目前已经是 Microsoft 自己的了。
- Wikipedia:4.5%,之前 GPT-3 就用了 English Wikipedia。
- Books:4.5%,作为对比 GPT-3 的数据源中 16% 来自书籍。
- ArXiv:2.5%,是学界最熟悉的开放电子学术论文存档库,由康奈尔大学于 1991 年成立。
- Stack Exchange:2%,类似于 Stack Overflow 的、针对程序员群体的在线技术问答社区。
LLaMA 的评估数据及表现
可以看到以上训练数据源,主要来自网络内容,因此 Meta AI 也说包含了冒犯、有害和带偏见的内容。所以 Meta AI 对该模型的偏见方面表现在 RAI 数据集上进行了评估,以衡量模型在性别、宗教、种族、性取向、年龄、国籍、残疾、外貌和社会经济地位等方面表现出的偏见。Meta AI 还根据提示模型的上下文的有害程度来衡量模型生成的毒性:
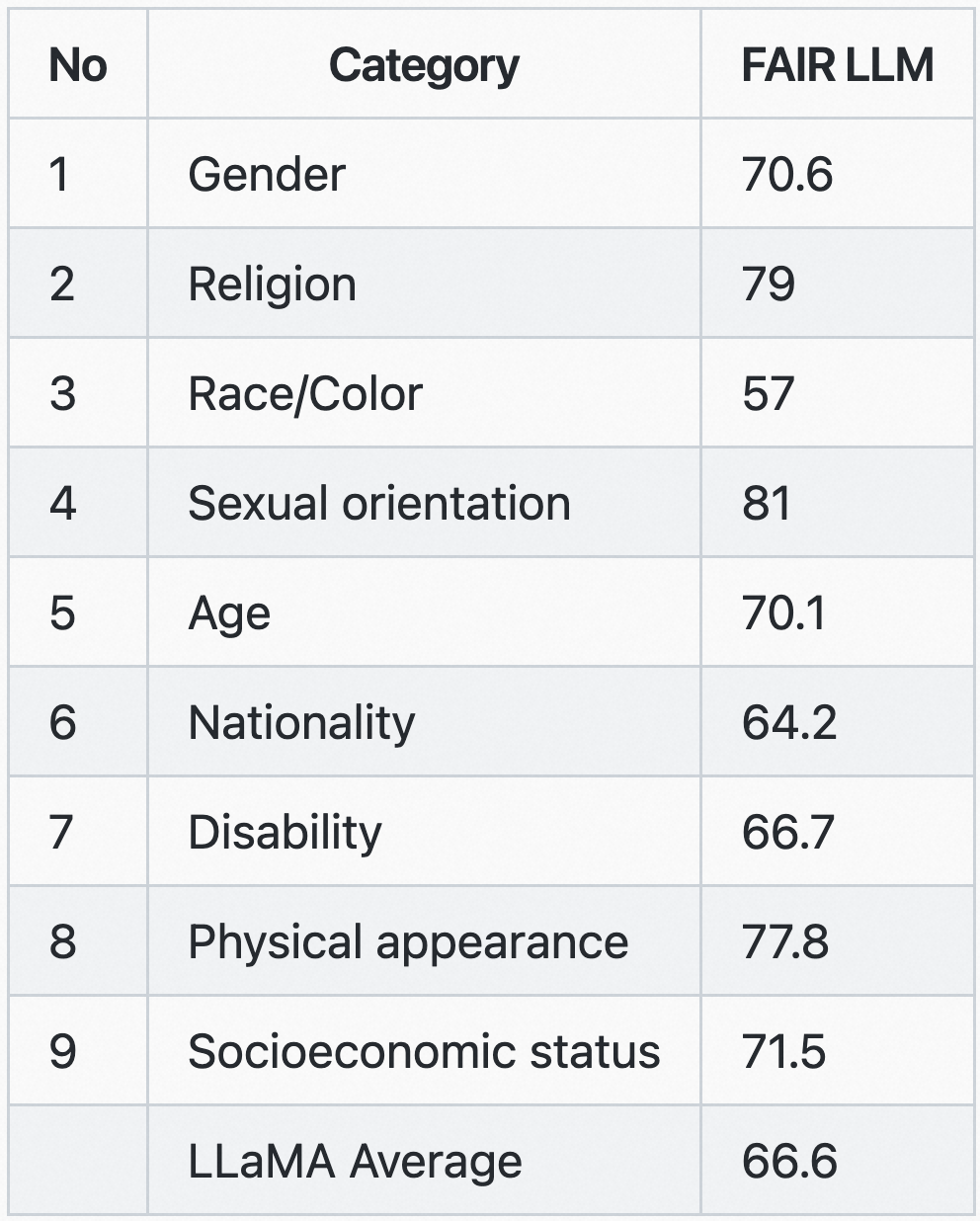
就像上面船长提到的,Meta AI 也对网络文本做了分类处理,如果其内容与 Wikipedia 或 Wikipedia 引用内容比较类似,则认为它是高质量的。这就像 GPT-3 认为 WebText 外链(Outbound Links)出去的且 Karma 大于 3 的网页是高质量的。这里 Meta AI 用到了 Kneser-Ney 语言模型和一个 fastText 线性分类器。
Meta AI 声称训练数据中包含 20 种语言,但大部分内容依然是英文为主,因此也与 GPT-3 一样还是在英文表现会更好。同样,OpenAI 曾声称因为英文内容多,所以整体模型生成的内容无形中就更符合英文母语人群的价值观,这也是一个潜在问题。
LLaMA 用到了如下这些评估数据集:BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC, OpenBookQA, NaturalQuestions, TriviaQA, RACE, MMLU, BIG-bench hard, GSM8k, RealToxicityPrompts, WinoGender, CrowS-Pairs。LLaMA 在其论文中罗列了大量实验结果,这里摘录一些。
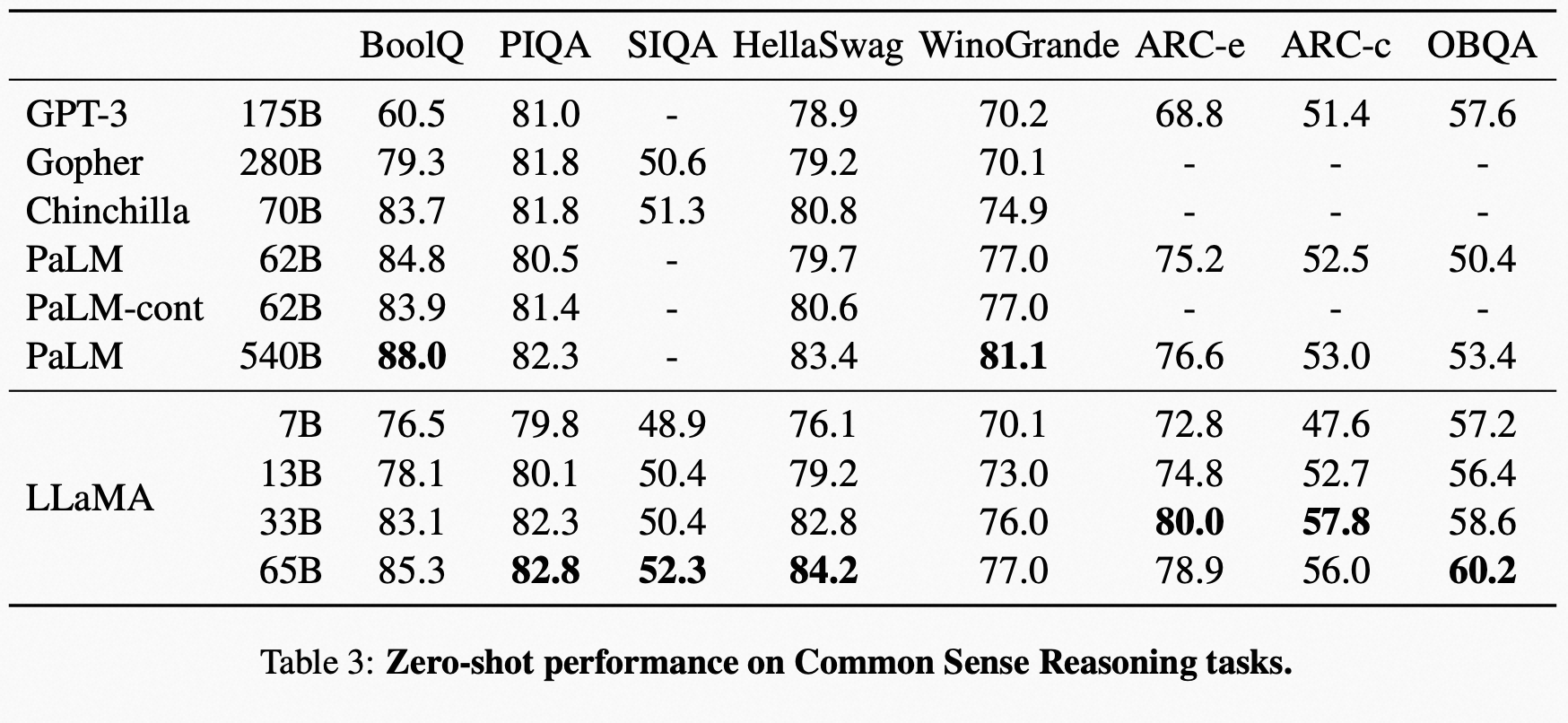
在一些推理任务上,LLaMA 有如下表现:
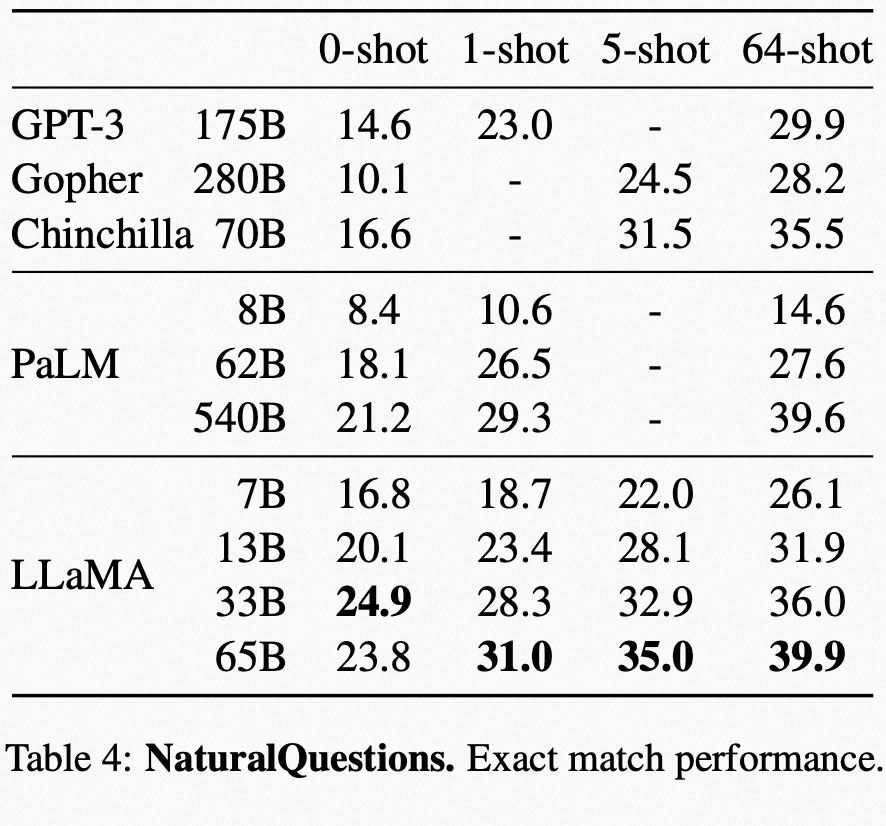
在 NaturalQuestions 上和其他模型对比的表现:
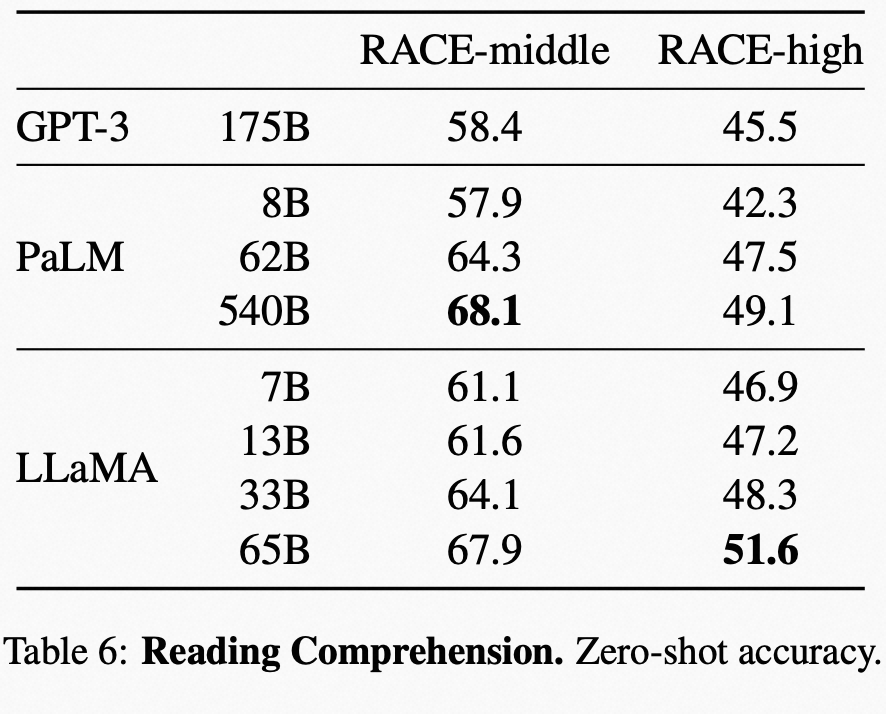
阅读理解上的表现对比:
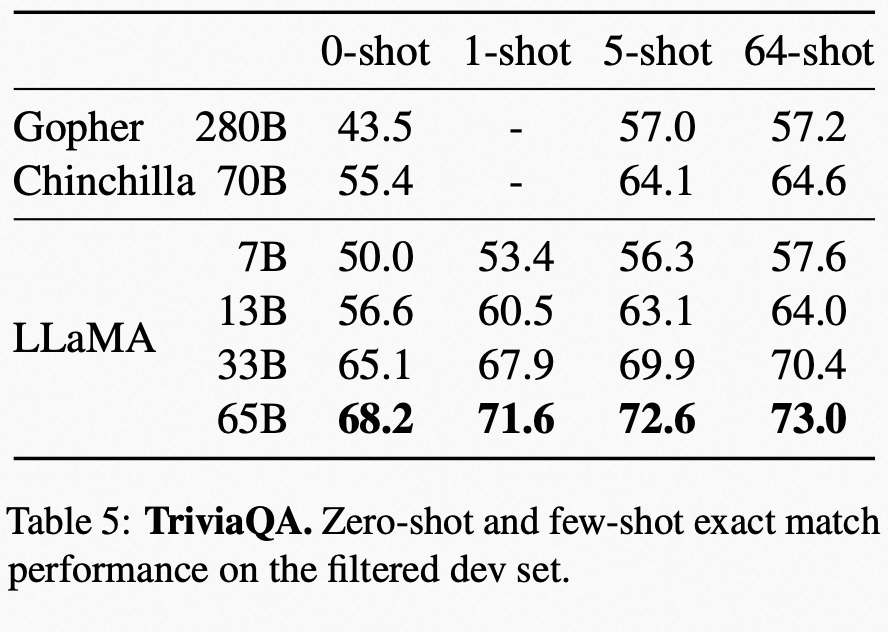
在 TriviaQA 上 Zero-shot、few-shot 对比问答效果的表现:
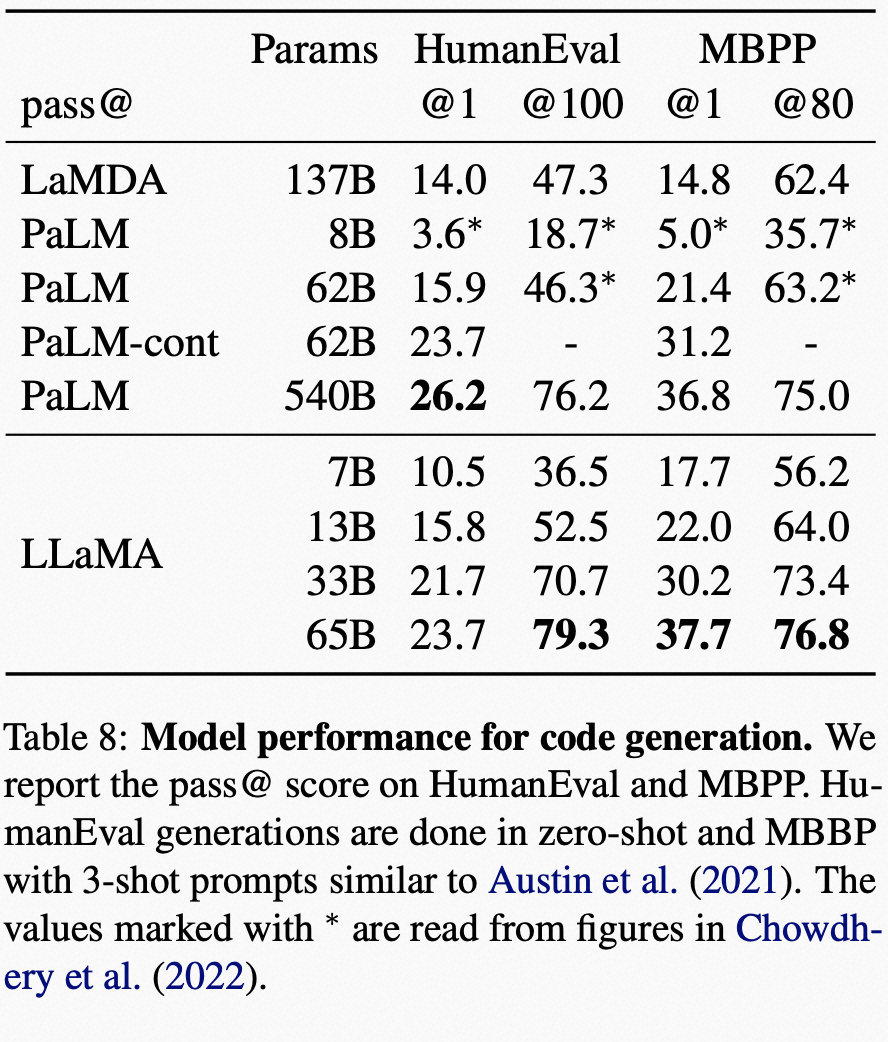
代码生成方面的表现对比:
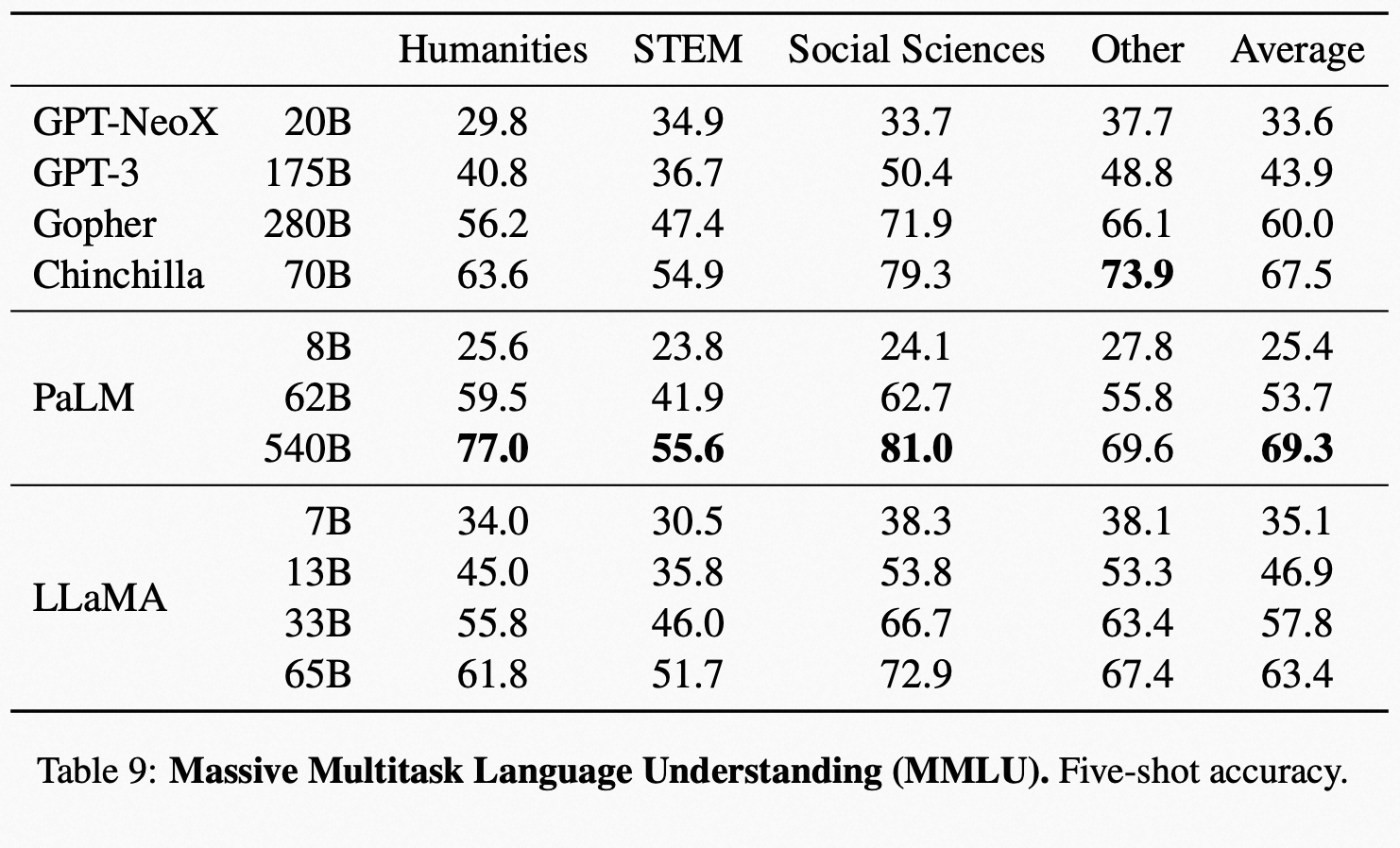
大规模多任务语言理解(MMLU)的表现对比如下,论文的附录 B 中 Table 16 中有完整的各模型表现,大家可以去查看。
3、算力
Meta AI 还给出了碳足迹的计算,来衡量算力的消耗情况,随着 LLM 应用的普及,这样的环保议题在未来会越来越被重视。
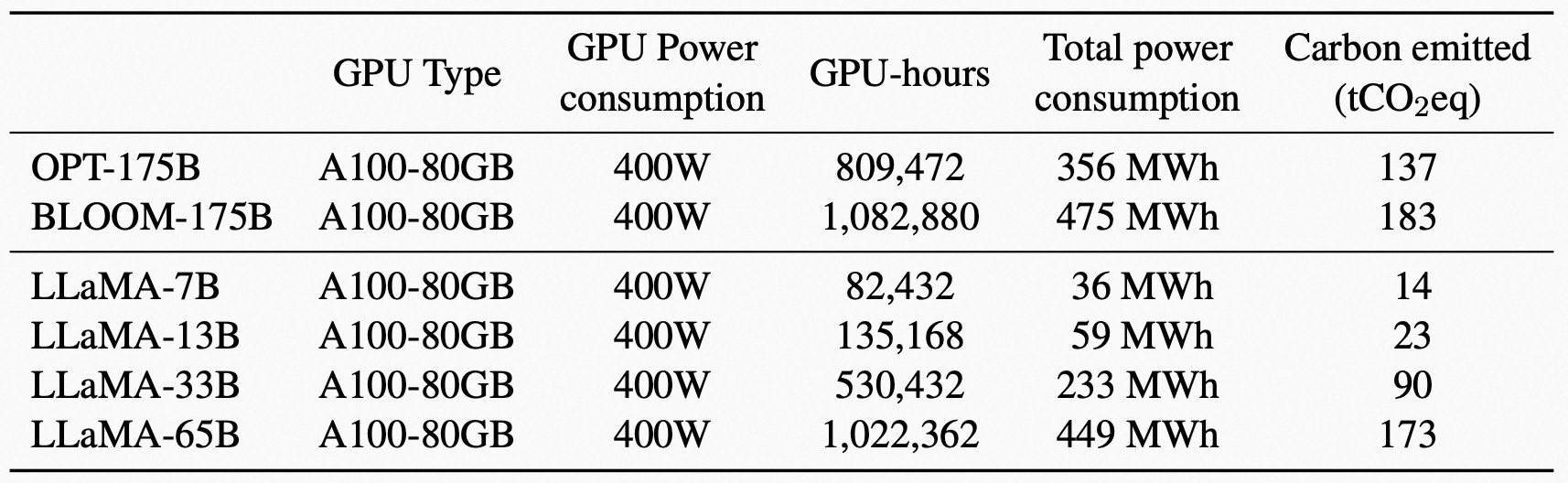
在同一数据中心训练不同模型的碳足迹。Meta AI 在同一数据中心训练 OPT、BLOOM 和 LLaMA 的模型的碳排放。对于 A100-80GB 的功耗,LLaMA 采用 NVLink 系统的热设计功率(TDP),即 400W。Meta AI 采用 PUE 值为 1.1,碳强度系数设定为美国国家平均水平的 0.385 kg CO2e/KWh。
4、一些评论与未来影响
Meta AI 这次直接开源了模型、参数,这次推动模型小型化、平民化,对于活跃 AI 领域的创业、研究都有巨大帮助,值得所有人重点关注。Meta AI 选择了周五发布,其实是让其他大厂措手不及,让这个事情在周末发酵一下。不过对于整个生态里大厂之外的所有人,这都是一件好事。
Meta AI 在论文中总结到,LLaMA-13B 的性能优于 GPT-3,同时体积更小超过 10 倍,而 LLaMA-65B 与 Chinchilla-70B 和 PaLM-540B 相当。与以往的研究不同的是,目前展示了仅使用公开可用数据集训练就可以达到最先进的性能,而无需使用专有数据集。Meta 希望将这些模型发布给研究社区,可以加速大型语言模型的发展,并帮助改进它们的鲁棒性并减轻已知问题,例如毒性和偏见。此外,Meta 观察到像 Chung et al. (2022) 论文中所提到的那样对模型进行微调可以获得更好的结果,Meta AI 计划在未来的工作中进一步研究。
Meta AI 还提到,目前实验来看,只要继续上参数规模、上数据规模,性能仍然还在涨,比如上图,所以 Meta AI 这次发布时直接表示,计划未来还会继续发布更大数据规模训练的、更大参数规模的模型。
5、能试玩吗?看看 LLaMA 给出的例子吧
LLaMA 还未开放,目前你可以在如下链接申请访问,进入 WaitingList:
- https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform
但是我们可以看看 Meta AI 放出的例子,也蛮有趣的。下面先是 LLaMA-65B(不用指令精调)的输出,加粗的部分是输入给的 Prompt(提示):

写推荐信:

给出 Python 函数定义和注释,续写代码:

Meta AI 团队调侃自己的老板 LeCun(hhhhh):

给定场景,虚构对话的能力:


Meta AI 还展示了几个 LLaMA-I 的生成示例,LLaMA-I 是使用 Chung et al. (2022). 的协议和指令数据集对 LLaMA-65B 进行微调后的结果。第一个是让 LLaMA 写一个太阳和冥王星的对话:

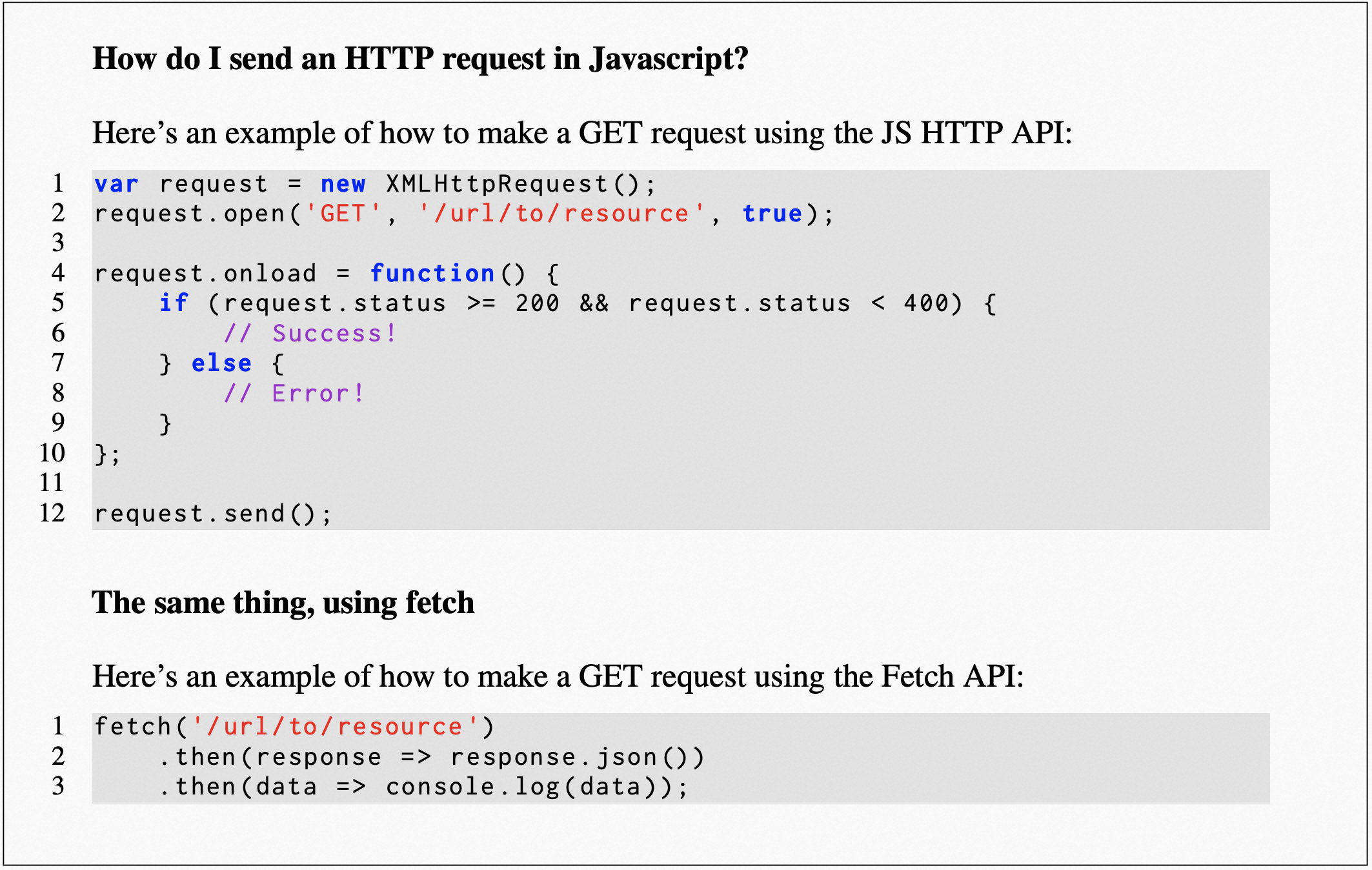
再让 LLaMA 写一个用 JavaScript 发送 HTTP 请求的代码示例:
用 Python 写一个正则表达式移除 HTML 标签,以及用 Python 写一个抽取函数定义的正则表达式如下(说真的,船长之前用 ChatGPT 写正则表达式,这效率真的太高了,人脑写东西其实挺反人类的):

一系列连续多轮对话的问答,LLaMA 也表现的很好:

写个小作文也不在话下:

瞎编一套理论解释猫从未存在过(研究人员的脑洞也挺大的 hhhh):

写一个凯撒大帝和拿破仑之间的吵架场景(2333333):

发送一封电子邮件,请求人们负责任地使用语言模型:

又是多轮的对话,并且涉及到大量真实实体,验证世界知识的准确性,可以看到模型准确给出了是爱因斯坦提出了质能方程的:

让 LLaMA 假装是一个可运行 bash 终端的:

示例就看到这里,还是非常令船长兴奋的。可以想见,2023 注定是群魔乱舞的一年,我们一定会在模型发展上看到很多载入 AI 发展史册的事件发生。
参考
- [1] Biao Zhang and Rico Sennrich. 2019. Root mean square layer normalization. Advances in Neural Information Processing Systems, 32.
- [2] Noam Shazeer. 2020. Glu variants improve transformer. arXiv preprint arXiv:2002.05202.
- [3] Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. 2021. Roformer: Enhanced transformer with rotary position embedding. arXiv preprint arXiv:2104.09864.
- [4] https://github.com/facebookresearch/llama
- [5] https://ai.facebook.com/blog/large-language-model-llama-meta-ai/
- [6] https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
- [7] https://twitter.com/ylecun/status/1629243179068268548
- [8] https://twitter.com/GuillaumeLample/status/1629151231800115202
- [9] Hyung Won Chung, Le Hou, S. Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Dasha Valter, Sharan Narang, Gaurav Mishra, Adams Wei Yu, Vincent Zhao, Yanping Huang, Andrew M. Dai, Hongkun Yu, Slav Petrov, Ed Huai hsin Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc Le, and Jason Wei. 2022. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416. 行数:174