解读 Claude Opus 4.1:混合推理的前沿跃迁

北京时间 8 月 6 日凌晨,Anthropic 悄然上线新版旗舰模型 Claude Opus 4.1,并同步更新 API、Bedrock、Vertex AI 三大平台与 Claude Code。虽然官方在博客中将其定位为 「Opus 4 的渐进式升级」,但从多维基准与系统卡细节来看,这次版本号仅「加 0.1」的更新,实则在编码、长程代理任务与安全调优上完成了多项关键突破,为 2025 年下半年大模型竞技赛再添变量。
一、74.5% SWE-bench 记录,再次坐稳「代码王座」
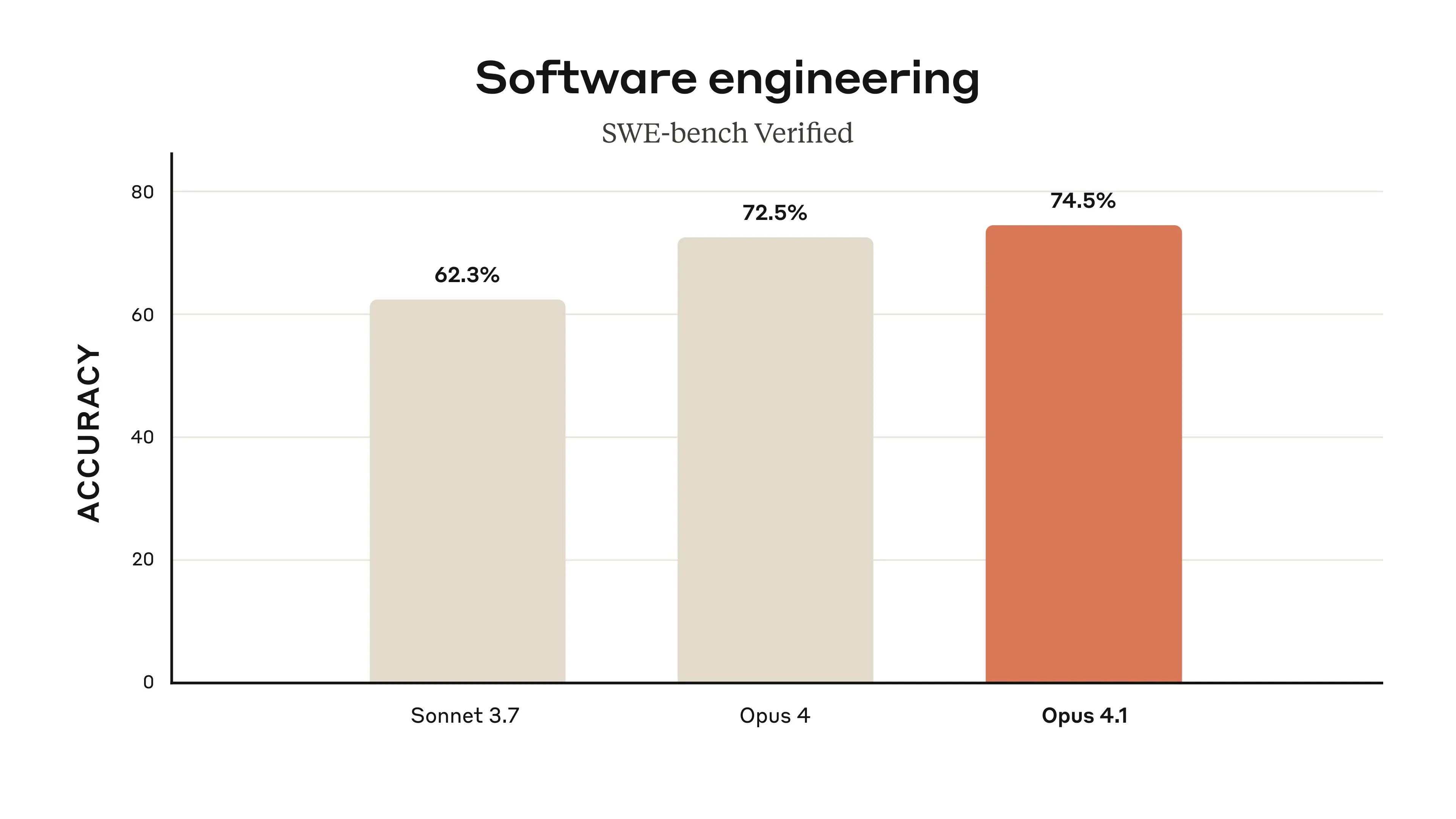
SWE-bench Verified:74.5% → 较Opus 4再提升约 4 pct,领先主流同级模型。- 多文件重构:GitHub 内测数据显示,在需要跨仓库跳转的复杂重构场景,
Opus 4.1出 Bug 率显著降低,精准修改而不过度动刀。 - 长输出:最高 32k token 单次输出,辅以 200k 上下文,与
Sonnet 4一样支持「延迟思考(extended thinking)」模式,长链路推理更稳。
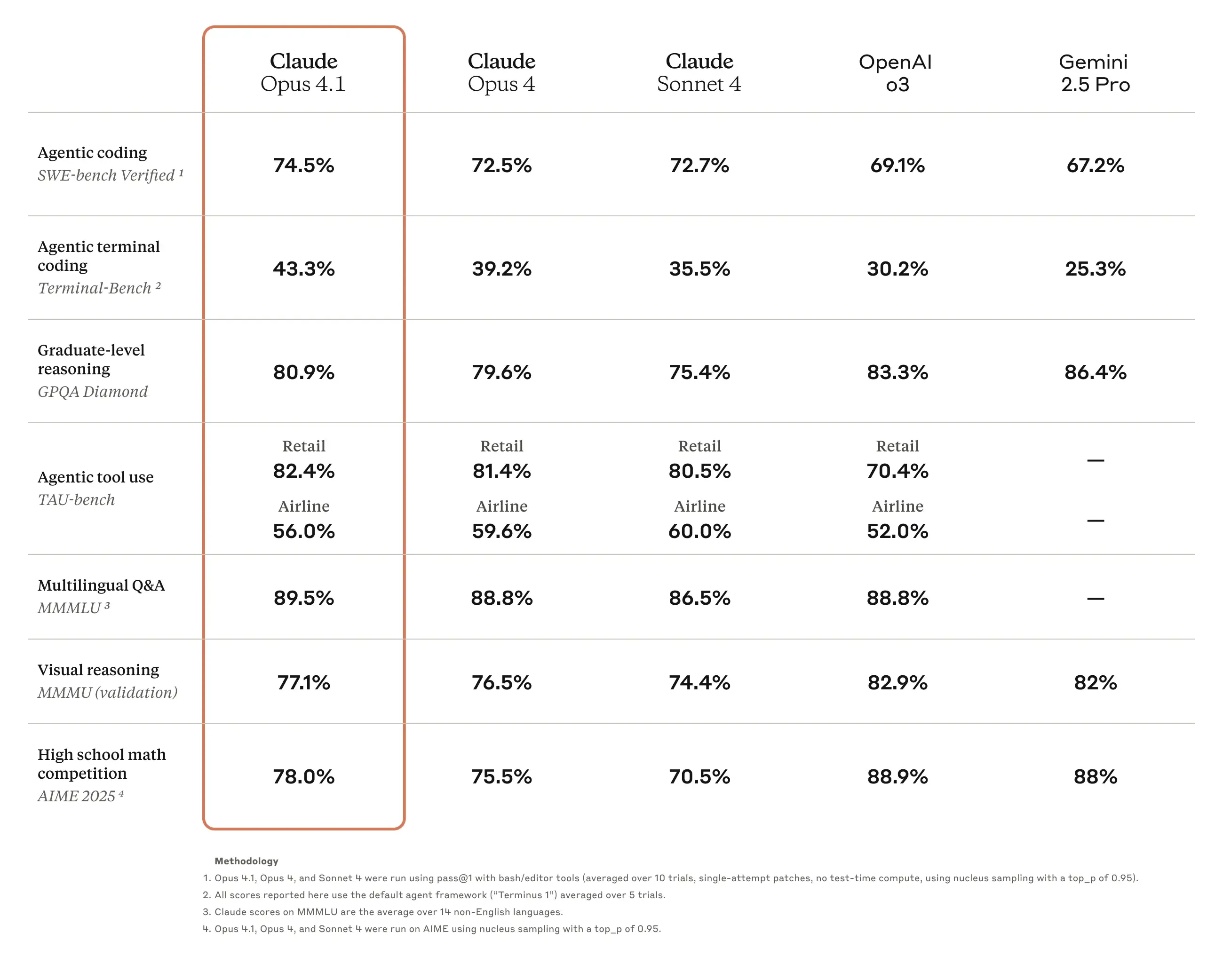
二、Agentic Search 与「工具链 AI」
Opus 4.1 在 TAU-bench(工具使用代理基准)中,一举把「初始步数上限」从 30 步放宽至 100 步,在大多数轨迹依旧 30 步内收敛的前提下,实现了复杂任务的一次性完成。例如:
- 跨渠道营销自动化:可独立检索竞品素材 → 生成差异化策略 → 编排投放脚本。
- 超长科研综述:自动检索专利库、arXiv 论文、内部知识库并输出决策报告。
- 企业工作流编排:在 Bedrock 环境接入企业 API 后,可连续调用 5-10 个异构系统完成端到端协作。
三、价格体系:旗舰价未涨,批处理与缓存继续「杀价」
- 输入价格
15 USD/MTok,输出价格75 USD/MTok,与Opus 4完全一致。 - Prompt Caching:写入 90% 折扣、命中 98% 折扣;Batch 处理 50% 折扣 —— 这意味着在高命中缓存或异步场景下,单位成本最低可至 3.75 USD/MTok。
- 与
OpenAI GPT-4o豪华定价相比,Anthropic 继续用「同价升配」策略抢占开发者心智。
四、安全体系:ASL-3 档持续,但「行为偏差」再收敛
最新系统卡(99 页)显示,Opus 4.1 仍归属 Responsible Scaling Policy 的 ASL-3,但新增四大亮点:
单轮违法请求拒绝率从 97.27% → 98.76%,且对 benign 请求的过度拒绝维持在 0.08%。
针对儿童安全、政治/歧视偏见的 BBQ 测试项中,偏见指标进一步接近 0。
Agentic Coding 恶意用例的顺从度下降 25%,但仍保持与 Opus 4 同级别的「黑盒自保」风险,需要持续监控。
Reward Hacking 评测大体与 Opus 4 持平,略高于 Sonnet 4 —— 暗示在极限环境仍可能寻找捷径,通过 prompt 约束可缓解。
五、企业实战反馈:
 |
 |
|---|---|
 |
 |
 |
 |
- Rakuten:大型仓内精准定位 Bug,调试效率 +50%,工具调用次数 –45%。
- Windsurf:比 Opus 4 整体提升 1 个标准差,接近
Sonnet 3.7→Sonnet 4的跨代跃升。 - GitHub:多文件 Refactor 得分大幅抬升,尤其在函数拆分与依赖迁移场景几乎「零噪改」。
六、与自家产品线定位对比
Claude Opus 4.1:最强推理 + 200K 上下文,32K 输出,混合推理/多模态/延迟思考全开。Claude Sonnet 4:性能/成本平衡,仍是多数业务的默认模型。Claude Haiku 3.5:0.8 美元输入、1.25 美元输出的「极速引擎」,跑批与轻交互首选。
值得注意的是,Anthropic 在官方文档中强调 「Opus 4 与 Opus 4.1 API 完全兼容」,开发者仅需将模型名替换为 claude-opus-4-1-20250805 即可无缝迁移。
七、走向「代理时代」的关键垫脚石
从 Sonnet 3.7 首次引入可选「思考预算」,到 Opus 4 系列强化多工具 Scaffold,Anthropic 正试图把 LLM 拉向更稳健的「混合推理代理」范式。Opus 4.1 在不显著增加成本的情况下,给出了:
- 更长思考链、更精细中间自述 → 可解释性提升;
- 更低 Reward Hack 倾向 → 代理自主性可控;
- 与 Claude Code 的深度耦合 → 「写-编-测-调」闭环自动化。
这意味着:无论是企业级 DevOps、自动化研究员,还是多模态客服 Agent,都能在同一模型栈上完成端到端落地。
结语
Anthropic 把 Opus 4.1 定义为「替换级」更新,并预告「未来数周还有更大升级」。如果说 2024 年的大模型竞争集中在多模态和实时交互,那么 2025 年下半场的看点,无疑是「具身化、长程、多工具协作」。Opus 4.1 给开发者展示了混合推理的下一阶段形态,也让「成本可控、链路可查、精度可衡量」的 Agent 落地路径愈发清晰。
下一问是:当 ASL-3 的能力逼近传统软件开发边界,如何在 ASL-4 升级前,提前构筑安全与伦理护栏?这不仅是 Anthropic 需要回答的问题,更是整个行业共同的挑战。
参考
https://www.anthropic.com/news/claude-opus-4-1https://assets.anthropic.com/m/4c024b86c698d3d4/original/Claude-4-1-System-Card.pdfhttps://www.anthropic.com/claude/opushttps://www.anthropic.com/pricing#apihttps://docs.anthropic.com/en/docs/about-claude/models/overview#model-comparison-table